
Migrating Big Data to the Cloud with WANdisco LiveMigrator, ADLS Gen2, Databricks and Delta Lake
By WANdisco
Jul 15, 2019
The rise of the cloud has seen the most fundamental shift in IT in many decades. When deciding where new capabilities will be developed and operate, the cloud is now the first choice for most enterprises.
This is increasingly true for big data. The accelerating consolidation of and diminishing opportunities for Hadoop vendors is directly related to the increasing use of cloud-native systems for storing and processing big data, where you can take full advantage of cheap, scalable storage and the flexibility that comes from the capacity and breadth of analytic platforms there. Big data has found a natural home in the cloud, and organizations are tasked with taking advantage of it.
Hardware maturity cycle signals the right time for big data to move to the cloud
The economic advantages of the cloud for new big data systems are clear, but there is also a key reason why it is the right time now for organizations to make the shift to the cloud. The level of interest in Hadoop peaked in June 2015, and has been declining ever since.
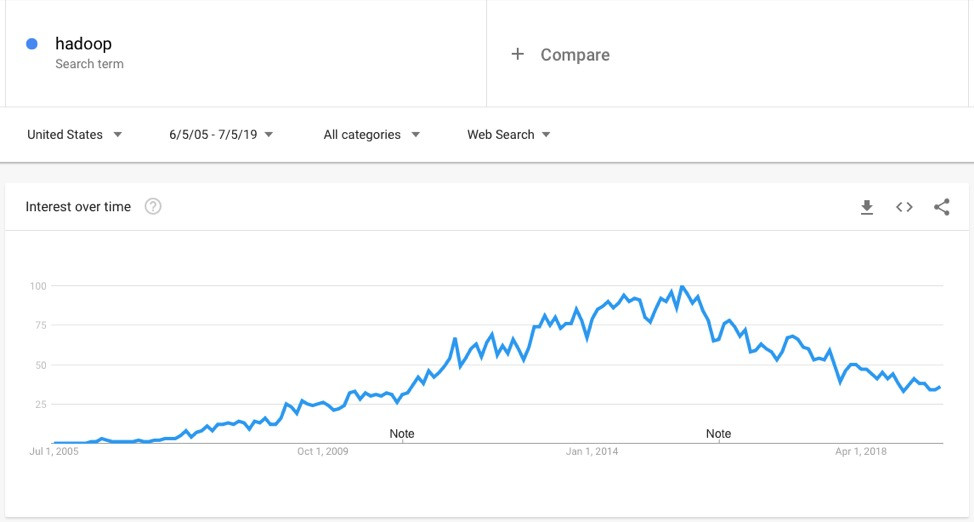
The significant capital investments companies made to build out data centers to host their Hadoop data and workloads have just now moved past the typical 2 to 4-year depreciation period, allowing those costs to be written off now. Shifting from capital hardware depreciation to operational expenditure for cloud becomes straightforward.
The Hadoop distribution vendors are seeing the effects of this now, with Hortonworks being consumed by Cloudera, who have since reported challenges in maintaining business growth. Similarly, MapR missed a self-imposed deadline of 3 July to secure new funding or attract a buyout, leaving the company at risk of staff layoffs and closure of its headquarters.
ON-DEMAND WEBINAR
WANdisco, Databricks and Neudesic partner to accelerate and simplify your Hadoop migration
In this webinar, our experts discuss the benefits of adopting an advanced analytics platform to drive aspirational business outcomes and how migration to this advanced platform can be achieved from a legacy of on-premises Hadoop environments without disruption to your ongoing business operations and without risk of data loss.
Technical drivers for shifting big data to the cloud
Cloud-native analytic capabilities
Compounding the challenges for traditional big data vendors is the level of investment in cloud-native platforms for data storage, processing, analytics and machine learning. The core outcomes that on-premises big data systems were designed to address have been surpassed by more nimble systems that can be purchased by the minute, with manageable costs and consumption.
Databricks is the perfect example of this shift. By providing a unified analytics platform built on open-source Apache Spark that offers managed options in the major cloud providers, including AWS and Azure, Databricks handles all of the analytic processes with ease that previously suffered under inflexible and cumbersome Hadoop deployments on-premises. Databricks combines capabilities for:
- Removing the devops burden of installing, running, scaling and maintaining Spark clusters that power large data engineering and machine learning projects,
- Sharing code among developers and data scientists with familiar notebook-based definitions that include revision history and GitHub integration,
- Automating product data pipelines with job scheduling, monitoring and debugging, and
- Deep integration with the tools that are familiar to existing users of big data platforms, so that adopting an open and extensible platform is as simple as possible.
Cloud Storage
Another key advantage of the cloud has resulted from innovation in storage. AWS S3 was the first cloud-native service, offering “infinitely” scalable storage at extremely low cost by being designed for global scale from the outset, and jettisoning many of the assumptions about storage system needs at scale. AWS have since provided big data-native cloud storage capabilities with EMRFS.
Equivalently, other cloud vendors have innovated in storage. Azure Data Lake Storage Gen 2 is a compelling advancement by combining the scalability of blob storage in Azure with the benefits of a hierarchical file system and the efficiency gains that come with using that for big data workloads. Managing very large directories of files is a typical Hadoop operational task that ADLS Gen 2 makes possible on top of the cost advantages that come with object/blob storage at scale.
As big data systems have increasingly delivered what dedicated data warehouse and analytic platforms offer, structured and semi-structured data usage has grown in Hadoop. Hive, Tez, LLAP, Spark and related technologies are being used in most big data deployments to offer familiar, SQL-like interfaces to big data, making developers, analysts and data scientists much more efficient. Most recently, these needs have grown to include transactional access to structured data at scale. Hadoop has responded with Hive ACID tables, while Spark has been able to take a lighter-weight and arguably more comprehensive response by innovating at the storage layer.
Delta Lake offers ACID transactions, scalable metadata handling, data versioning, schema evolution and a unified approach to batch and streaming data ingest for Spark environments, and is a native capability of the Databricks platform. It is an open source storage layer and analytics engine that brings reliability and unmatched scale to data lakes, running on top of existing HDFS or cloud storage, and maintaining compatibility with Apache Spark APIs.
The challenges of moving to the cloud
With such compelling advantages, timing and market forces for big data in the cloud, what prevents organizations from adopting it today? We see three common impediments to cloud adoption for big data:
- The sunk cost of existing skills, infrastructure and systems built using on-premises Hadoop infrastructure,
- Data gravity, and
- The rise of enterprise use cases for big data with strict SLAs.
The first impediment is obvious: companies have invested in not just the capital cost of hardware needed to run Hadoop clusters in their data centers, but in the people, processes and applications that work there too. Moving away from these sunk costs is difficult without an easy path to smooth the transition to better technologies, cost structures and opportunities.
The second impediment is well-understood also: data has gravity, and tends to accumulate because there is value in adding to existing data sets instead of federating them. Data attracts other data. The challenge this poses is that, at scale, moving data becomes a difficult problem. Large data sets take time to move, and while that is occurring, change and ingest is still needed, which can (without the right technology) make it impossible to move large scale data sets to the cloud.
The third impediment is related to this. As Hadoop has matured, organizations have brought increasingly mission-critical workloads to it because of the benefits it has provided for scale and fit for purpose. Enterprise-critical workloads bring with them expectations of availability, consistency, security, auditability and the like. On the spectrum of complexity, moving cold, static datasets is simple, while moving changing datasets with enterprise SLAs on these expectations is very challenging.
Addressing the Challenge
An answer is needed to the significant challenges for migrating enterprise big data systems to what is clearly a better place: the cloud. More specifically, an answer is needed for how organizations can take advantage of a unified analytics platform in the cloud without disrupting their business operations just to do so.
WANdisco introduced LiveMigrator in June to fulfill this need. By combining techniques for migrating large-scale data in a single pass, without disrupting new data ingest or changes, and ensuring completely consistent data as a result of migration, it addresses the impediments of data gravity and enterprise SLAs. You can use LiveMigrator to move your data lake to the cloud without downtime or service disruption.
That leaves just the impediment of the sunk costs of skills, infrastructure and systems built on-premises in Hadoop. Databricks provides an elegant answer to this challenge by offering more capable technologies for applications and systems to operate against big data in the cloud. Users, data scientists and administrators can become more productive and deliver better outcomes faster. Delta Lake provides the storage and processing layer on top of cloud storage to support enterprise workloads across streaming and batch requirements to better manage data lakes at scale.
Combining WANdisco LiveMigrator, Databricks and Delta Lake is a natural response to the challenges of migrating big data to the cloud. The remainder of this blog post walks you through the hands-on elements of doing exactly this, with a use case for a retail organization that needs to continue processing business-critical information at scale, 24x7 in their Hadoop environment, but also wants to move this data and processing to a modern, cloud-centric architecture.
Neudesic and WANdisco will deliver
Free Cloud Migration Jumpstart Offer including architectural design session and pilot migration of up to 5TB of data while keeping both environments in sync using WANdisco without imposing downtime or disruption to on premise services which will remain fully operational during migration.
Following this process:
- Architectural Design Session (3 Days Free for qualified customers) — validate a use case, design future state and select pilot scope
- Pilot Migration (1 Week Free) — Neudesic will leverage WANdisco to migrate up to 5TB of data
- Full Migration (Priced Separately, 2-4 Months) — Migrate remaining data
- Analytics (Priced Separately) — Unlock advanced Azure workloads for Analytics including Databricks
An Example
The practical example that we are using to show how simple it is to bring on-premises Hive content into Delta Lake for Databricks processing consists of:
- An on-premises HDP 3.1 cluster, running HDFS 3.1.1, YARN 3.1.1, Tez 0.9.1, Hive 3.1.0, Pig 0.16.0, and ZooKeeper 3.4.6,
- An Azure Data Lake Storage Gen 2 account,
- An Azure Databricks 5.3 cluster running Scala 2.11, Spark 2.4.1 and Python 3, and
- WANdisco LiveMigrator running on the WANdisco Fusion 2.14 platform.
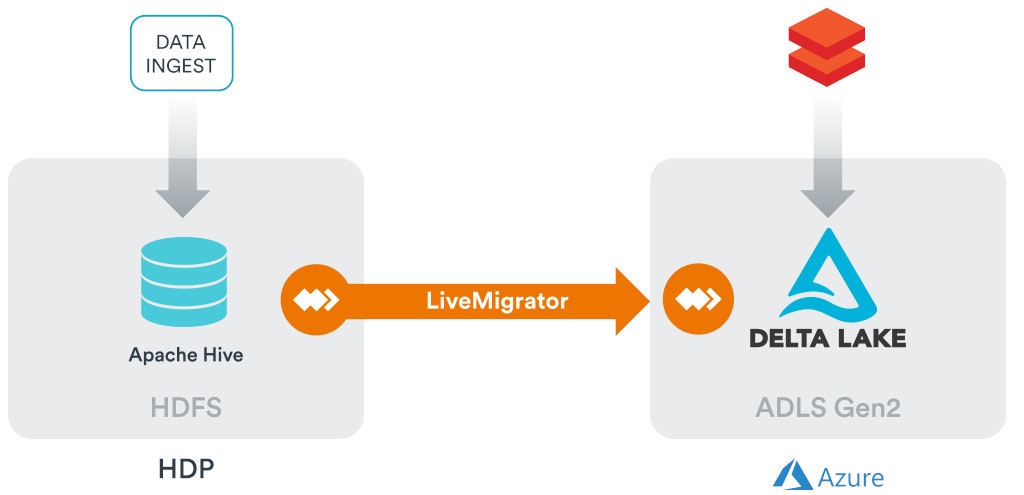
Figure 1: The example components
The scenario used for this example includes:
- Migration of data form HDP 3.1 with Apache Hive to Azure Databricks using Delta Lake,
- The user’s selection of specific initial data for migration, and the availability of that data for processing in Databricks in Delta Lake format, and
- The process that brings changes made to the data on-premises to Delta Lake.
WANdisco replicated Hive content—as it changes, and without the need for scheduled jobs to copy content—from the on-premises cluster to a staging area in ADLS Gen 2, and automates the process of merging those stages updates into Delta Lake tables.
Data that are made available in Azure via LiveMigrator represent a completely consistent replica of selected data in the HDP environment. The staging content follows the data formats, structure and relative locations in directories under the paths chosen for the donor and beneficiary systems (HDP and Azure). WANdisco automates the process of merging that data into a silver stage, from which regular processing steps can be conducted in Databricks for either immediate query and analysis, or continued aggregation and processing. This is depicted below.
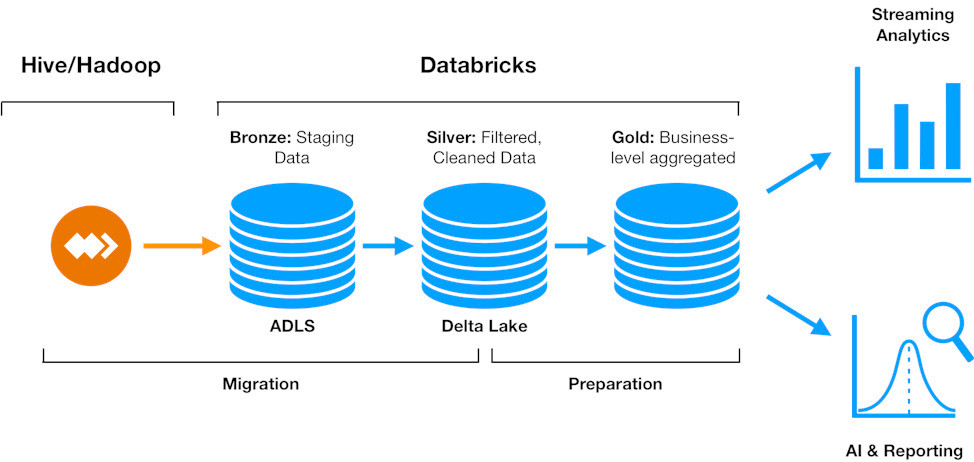
Figure 2: The data migration + processing pipeline
Example Setup
WANdisco LiveMigrator is installed on the HDP 3.1 environment first, which requires:
- Downloading the product from WANdisco (matching the installer version to that required for the operating system of the machine on which it will be installed and the Hadoop version in use,
- Running the installer for the Fusion platform by following the installation process described at https://docs.wandisco.com/bigdata/wdfusion/2.14/#doc_install
- Following Fusion platform installation, running the installer for the Live NameNode Proxy to integrate Fusion with the HDP cluster by following the process described at http://docs.wandisco.com/bigdata/wdfusion/plugins/nnproxy/4.0/#_installation
- Following Live NameNode Proxy installation running the installer for LiveMigrator.
WANdisco LiveMigrator is installed on the Azure environment secondly, which requires:
- Downloading the product from WANdisco, selecting the installer version to match ADLS Gen 2 and the operating system of the virtual machine on which it will be installed in Azure,
- Running the installer for the Fusion platform by following the installation process described at https://docs.wandisco.com/bigdata/wdfusion/2.14/#doc_install. You will need to provide the credentials and configuration details for your ADLS Gen 2 storage account.
- Following Live NameNode Proxy installation running the installer for LiveMigrator.
After installation, login to the Fusion user interface for LiveMigrator in the on-premises environment:
And induct the LiveMigrator instance for Azure to the on-premises instance by supplying its hostname in the “Induct a new node” option:
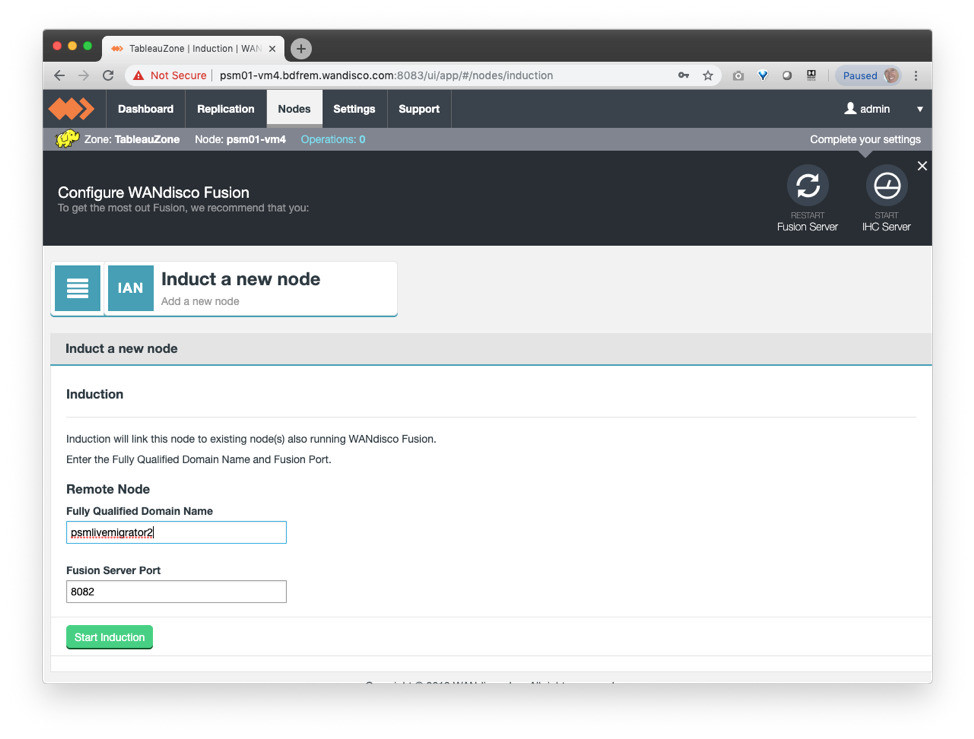
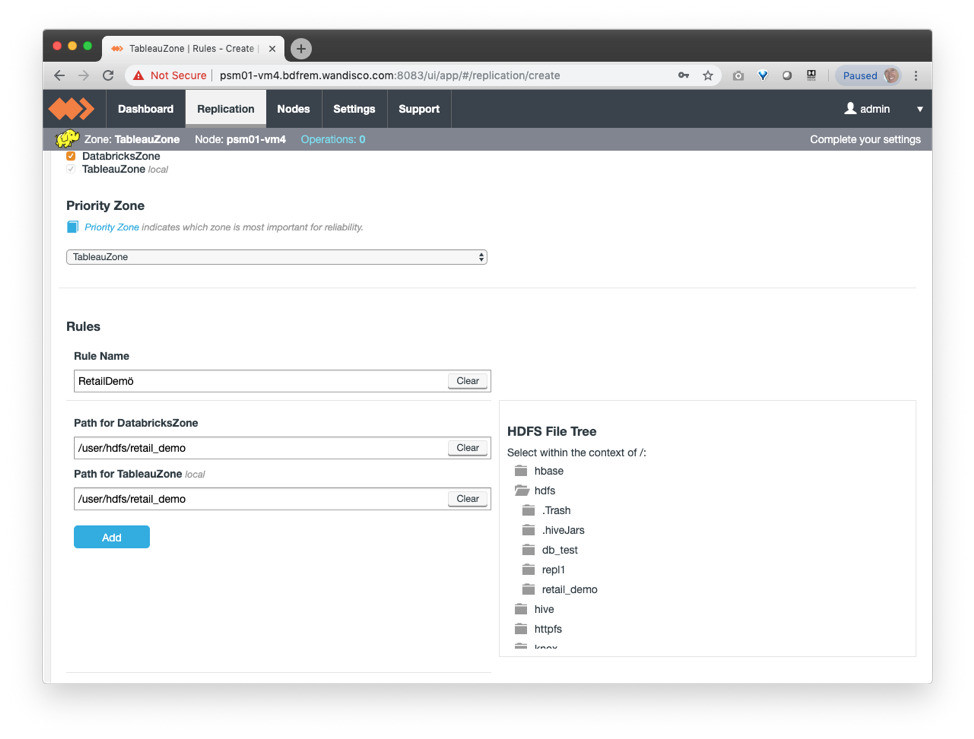
Once inducted, create the replication rule that defines the data that you want to migrate to the Databricks environment, selecting the location of your Hive dataset to be migrated. This is likely to be the location of your entire Hive data-warehouse, specific external table locations, or a specific database or table within Hive:
Initiate migration of your data using LiveMigrator:
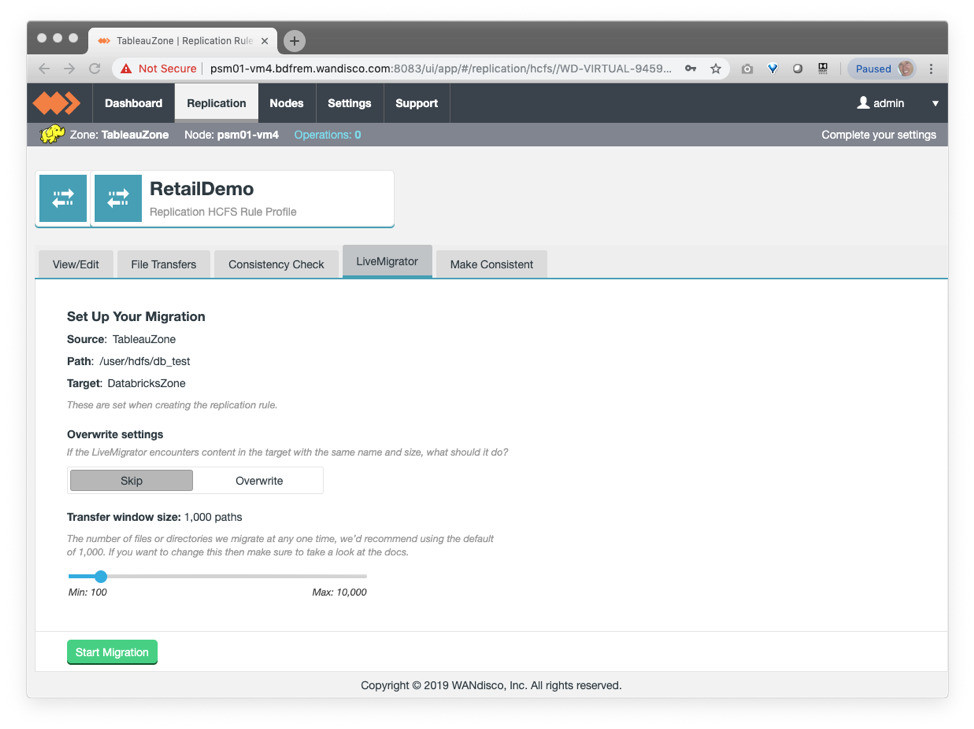
Your data now reside in your ADLS Gen 2 storage account, and will continue to be updated with any changes made in the Hadoop environment for the location that was migrated. LiveData replication is in effect.
Create a notebook in Databricks and configure access to your ADLS Gen 2 storage:
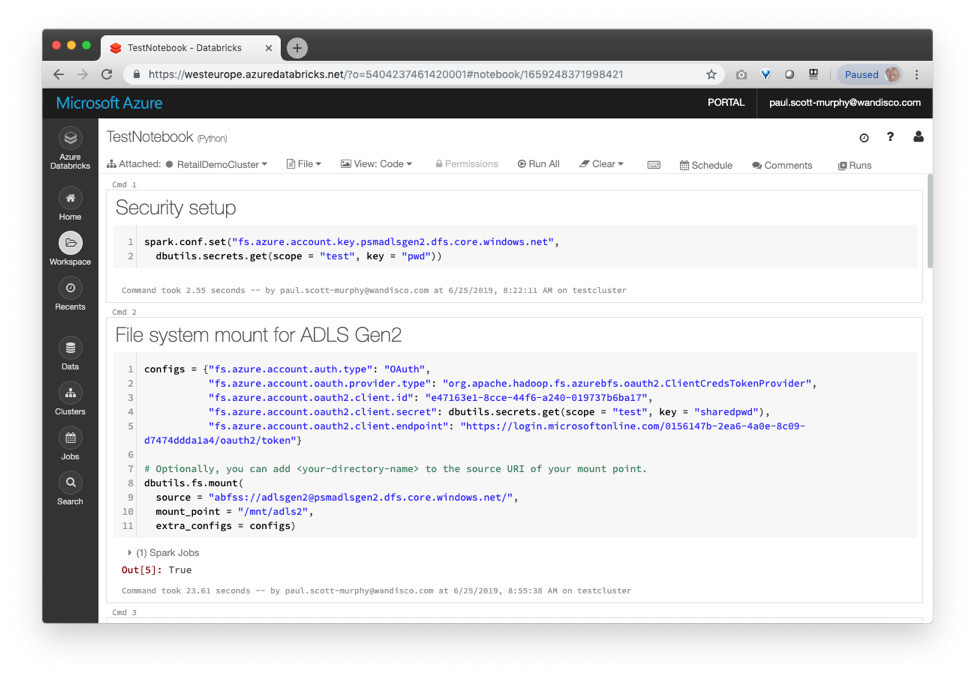
From that point forward, any changes in your Hive data on-premises can be merged automatically by WANdisco into your Delta Lake table to drive the final stage of your data processing pipeline in Databricks as you see fit.
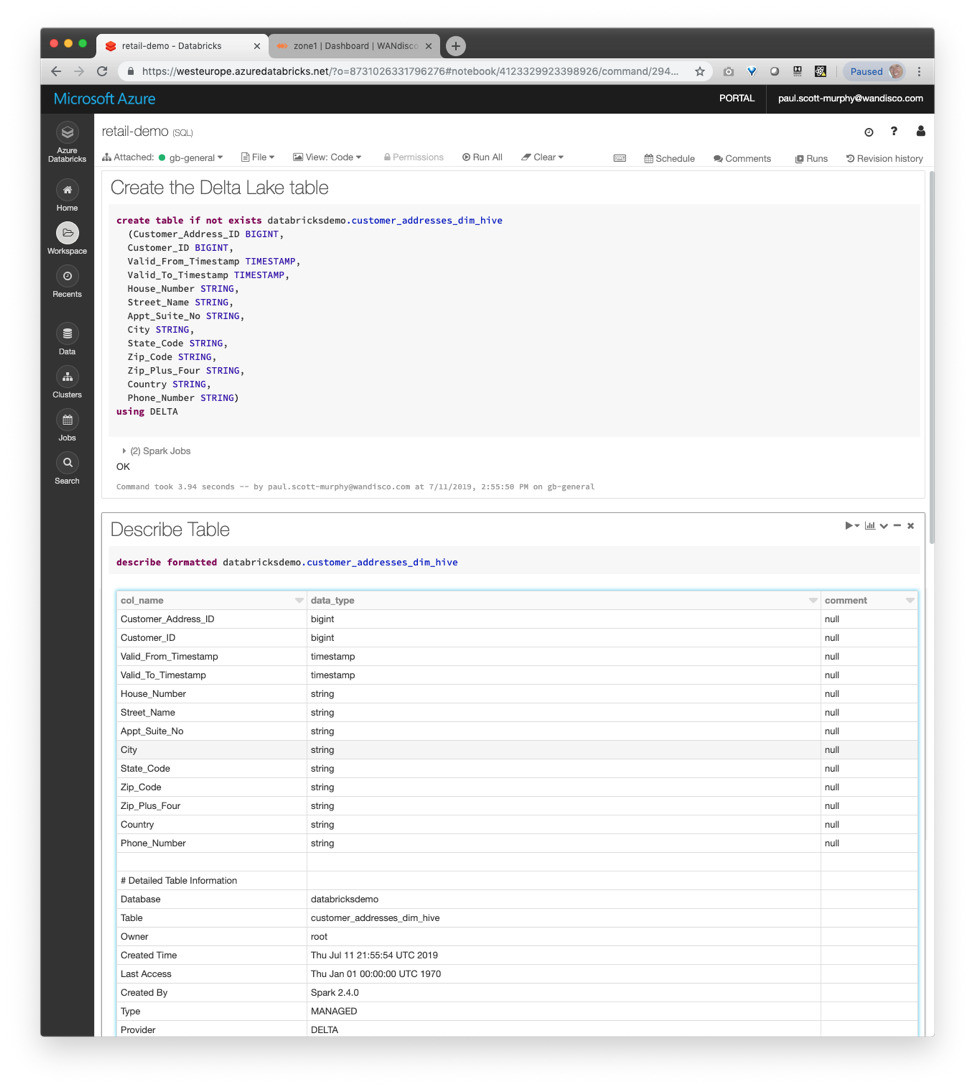
Subsequently, modified content in your on-premises Hive tables, perhaps by inserting to a table or partition, become available immediately in Delta Lake, which retains all aspects of versioning, time travel, ACID behavior and more that make it a rich foundation for large-scale analytic processing in the cloud.
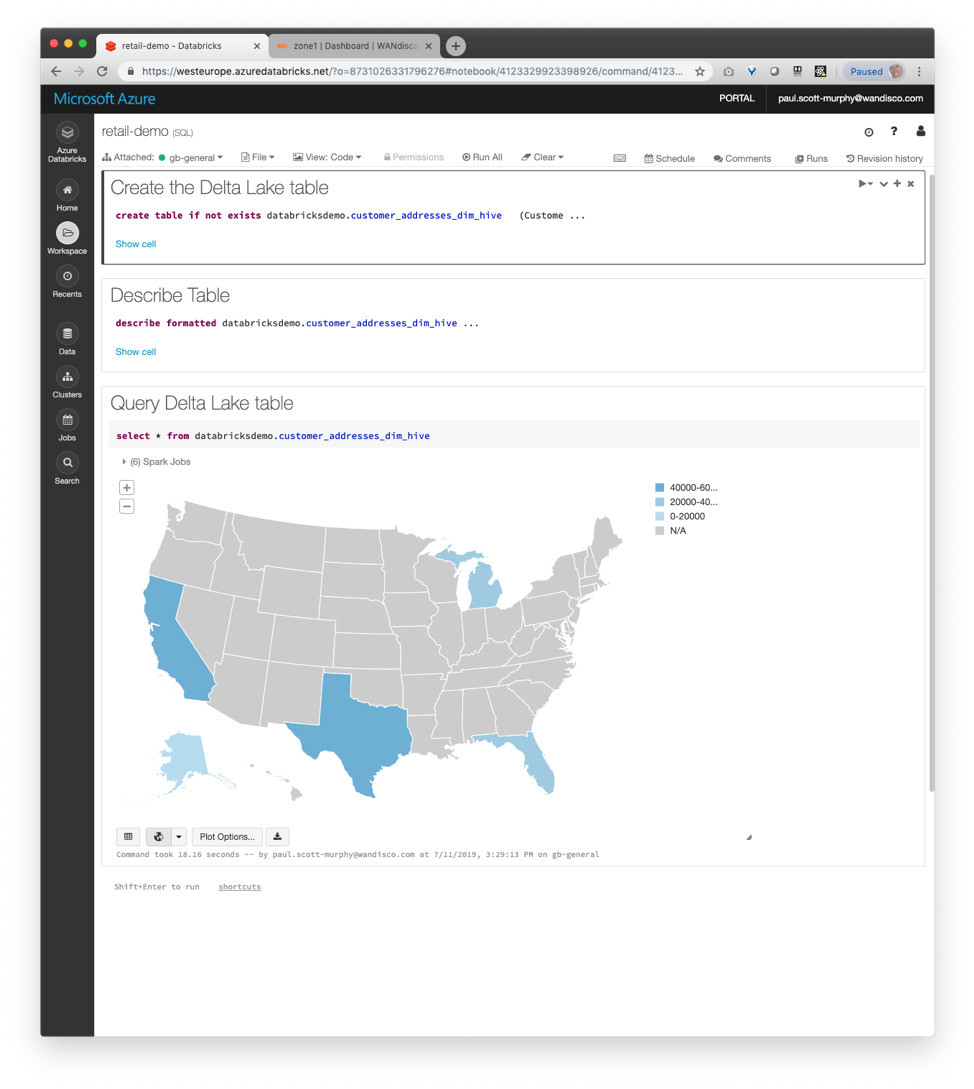
Feel free to use any of the wealth of analytic techniques and tools that you have available from Databricks. The processing power of the Apache Spark environment combined with ADLS Gen 2 and Delta Lake should provide capabilities well beyond what was possible using HDP and Hive on-premises, and you can use them all immediately on the most up-to-date version of your on-premises data.
Summary
Take advantage of a non-disruptive approach to migrating to a modern analytics platform in Azure with ADLS Gen 2, WANdisco LiveMigrator, Databricks and Delta Lake. Eliminate the risk of needing to cutover your applications at the same time with the ability to maintain LiveData between Hive and Delta Lake. Migrate your selection of data, and bring your processing workloads to Databricks over time without needing to disrupt existing operations in Hadoop or Hive.
To capitalise on this opportunity, WANdisco and Neudesic, a nationally recognised business and technology consulting firm, have partnered to deliver best-in-class service for customers looking to migrate to Databricks from on-premise data centers.
