
Azure Data Factory and WANdisco LiveData Platform for Azure – Better Together
By Tony Velcich
Jul 20, 2020
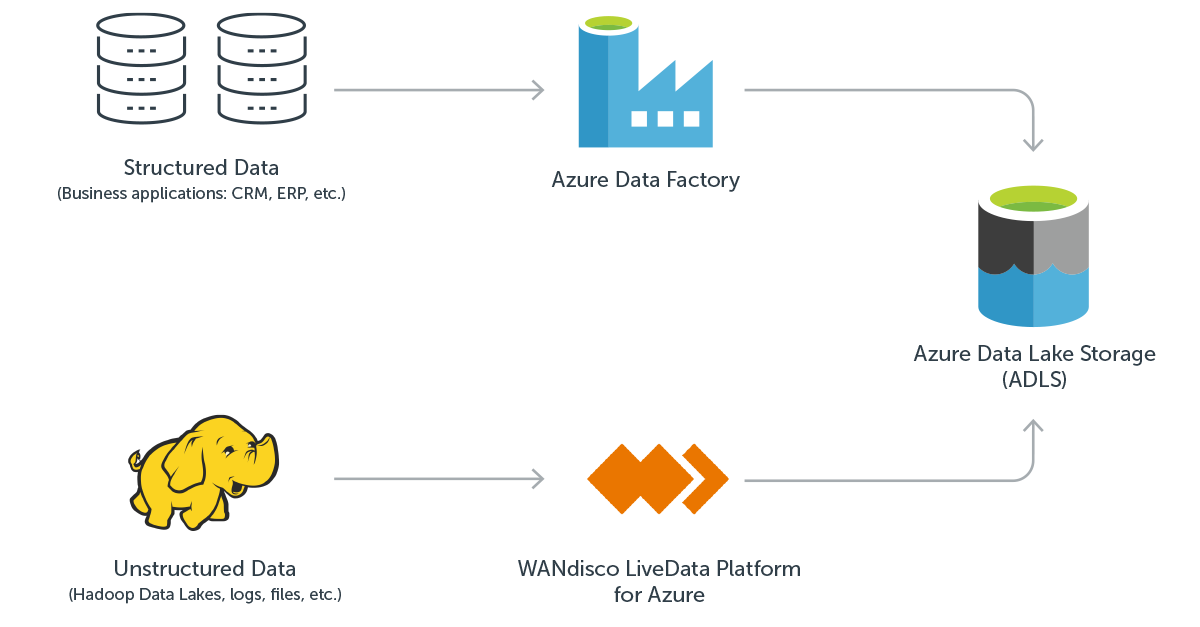
Azure Data Factory (ADF) is a cloud-based data integration service that enables data engineers to create, schedule and orchestrate data driven workflows to ingest data from disparate data sources into Azure. ADF allows engineers to develop complex extract, transform and load (ETL) or extract, load and transform (ELT) processes, and publish the data into targets such as Azure SQL Data Warehouse for use by business intelligence applications.
ADF provides a series of interconnected systems to form an end-to-end platform. The key components enable ADF to connect and collect data from disparate sources, and to transform and enrich data into the specific structure or schema needed by the targets. To make this easier ADF supports many pre-built connectors for the most common sources to enable data engineers to perform Copy, Data Flow, Look-up, Get Metadata, and Delete activities. Supported connectors include Azure sources, as well as multiple third-party databases including Amazon Redshift, DB2, MySQL, Oracle and many others. Connectors are also available for specific services and applications such as Salesforce, Microsoft Dynamics, Oracle (Eloqua, Responsys & Service Cloud), SAP and others. The full list of supported data stores can be found in the ADF documentation here.
ADF enables data engineers to transform and process the source data into predictions and insights, as well as to formats required by the target systems. Transformation activity takes place in computing environments such as Azure Databricks, Azure HDInsight, or can be performed natively in ADF with mapping data flows. Data flows allow engineers to develop graphical data transformation logic without writing code.
All of these capabilities make ADF ideally suited for connecting, collecting and transforming data to build data ingestion pipelines and bring structured data into Azure and make it available to analysts, data scientists, and business decision makers.
What about data residing in on-premises data lakes?
There are hundreds of exabytes of data that still reside in on-premises data lakes. How can that data be moved to Azure and correlated together with data published by the ADF data ingestion pipelines described above?
ADF does provide an option to copy HDFS data. However, this uses DistCp (distributed copy) to copy files to Azure. DistCp was designed for inter/intra-cluster copying, not large-scale data migrations, and introduces a number of issues that do not make it a good option for migrating large scale data lakes to Azure. DistCp operates in batch mode and doesn’t guarantee data consistency if data is actively changing. Any changes made to source cluster data while the DistCp migration process is running may be missed and must be subsequently identified and moved to the target cluster. For large scale data lakes with actively changing data, this reconciliation process can be lengthy, resource intensive, and very costly. One way to avoid this reconciliation process is for the source system to be taken offline during the migration process. But, for large-scale data migrations, the amount of downtime and business disruption that would be required is almost always unacceptable.
Announcing LiveData Platform for Azure
For these reasons Microsoft partnered with WANdisco and recently announced the WANdisco LiveData Platform for Azure, a new service offering available on Microsoft Azure. LiveData Platform maintains data consistency across distributed environments even while the data is actively changing. Deep integration with Azure resources such as the Azure Customer Portal, CLI, as well as with other Azure security and manageability features enables LiveData Platform to be deployed at the same time and managed in the same fashion as native Azure services.
WANdisco also announced two service offerings available exclusively on WANdisco LiveData Platform: LiveData Migrator for Azure and LiveData Plane for Azure. These offerings provide verified consistency for data replicated across on-premises Hadoop storage and Azure Data Lake Storage. LiveData Migrator performs the initial migration with a one-time scan of the source, and LiveData Plane ensures that ongoing changes are replicated and data is kept consistent following the initial migration. With WANdisco, the source systems can remain active and WANdisco’s patented Coordination Engine ensures that any changes are synchronized across all participating environments. WANdisco LiveData ensures:
- zero business disruption,
- zero data loss,
- and 100% data consistency,
which is why WANdisco LiveData Platform is Microsoft’s preferred solution for data lake migration to Azure.
Better Together
The combination of ADF and WANdisco LiveData Platform provide a complementary and complete data management solution when used together. ADF provides the ideal solution for connecting, collecting and transforming data to build ETL and data ingestion pipelines, while WANdisco LiveData Platform for Azure is the only solution that can migrate petabyte scale data lakes to Azure with no application downtime and verified consistency even if the data is actively changing.
About the author

Tony Velcich, Sr. Director of Product Marketing, WANdisco
Tony is an accomplished product management and marketing leader with over 25 years of experience in the software industry. Tony is currently responsible for product marketing at WANdisco, helping to drive go-to-market strategy, content and activities. Tony has a strong background in data management having worked at leading database companies including Oracle, Informix and TimesTen where he led strategy for areas such as big data analytics for the telecommunications industry, sales force automation, as well as sales and customer experience analytics.
